PostScript® 1.0 - A Code Study
In December 2022, Adobe, through the Computer History Museum (CHM), released the source code for PostScript®, version 1.0. PostScript is one of the foundational technologies of the desktop publishing revolution of the early 1980s, along with laser printers, the graphical user interface of the Apple Macintosh, and Aldus PageMaker. PostScript is a programming language and a page description format for translating visual content into printed documents.
Adobe immediately enjoyed business success through licensing PostScript to laser printer manufacturers and it became the de facto digital publishing format. While multiple histories have studied this event through a business lens, what historical questions may be answered through the source code? Further, as software practitioners, what can we learn from the source code to apply to present and future designs?
We argue:
- PostScript’s design and implementation benefited from a long lineage of other software programs (as Adobe has always admitted),
- The software architecture aligned with the interests of creatives, printer services, and printer manufacturers,
- Design choices, including modularity and semantics, added value to the product, and
- Pursuing the “print anything” objective, rather than page printing throughput, yielded a superior implementation.
A note on trademarks: PostScript® is a trademark of Adobe Inc. For reading clarity, we will omit the registered trademark symbol for the remainder of the article.
Table of Contents
- Background and Article Outline
- Timeline
- Developers and their Influences
- Development and Test Environment
- Design and Source Code
- Interesting Algorithms and Designs
- Alternative Paths / Competitors
- "Print Anything" Philosophy
- Deployment and History after Version 1.0
- References
Background and Article Outline
The origin story of Adobe has been told many times. In short, Charles Geschke and John Warnock left Xerox PARC to co-found Adobe after being frustrated at Xerox’s seeming disinterest in marketing their publishing technologies. Steve Jobs needed software for Apple’s upcoming laser printer and, after seeing what Adobe was developing, convinced the two founders to license their software. Other laser printers similarly licensed PostScript and with the release of the early Macintosh and Aldus Pagemaker, the desktop publishing revolution was born. Two extended write-ups of this story are Pamela Pfiffner’s Inside the Publishing Revolution: The Adobe Story, which is a 2003 book-length business history, and Tekla Perry’s 1988 Spectrum article, Inventing Postscript, the Tech That Took the Pain out of Printing, which focuses more on the engineering efforts and prior art.
At its core, the PostScript interpreter reads in a PostScript program that describes the desired printed pages and then the interpreter renders each page as a raster image to a device, typically a printer. Graphics are composed of paths, which may be straight-lines or curves and may be furthered defined by strokes, fills, or masks. The graphics model is described in the “Red” book, but PostScript closely follows a model by (Warnock and Wyatt 1982) shortly before Adobe was founded. Text is rendered as paths, with some clever techniques required to produce high-quality typography. Long treated as an Adobe trade secret, John Warnock described the font rendering algorithms in an article for the American Philosophical Society (Warnock 2012). The approach is based on modifying the character outlines, subject to constraints (“blue” and “yellow” hints) and an erosion process, to better align with the raster grid and aesthetic needs.
Within this article, we will first present two timelines. The first contextual timeline will place the development of the code in the larger history of the desktop publishing revolution. The second timeline will focus on the development of the source code. Secondly, the article will cover biographical details of the developers and what education and work experiences they brought towards the development. Then, we will cover the development process and resources available to the development team.
Turning to the source code, we will examine how it is designed and implemented. PostScript pushed forward the state of the art and we will cover some illustrative examples (although Adobe has kept some details as trade secrets and many aspects were developed after the 1.0 release). Finally, we will compare the design to competitor’s designs and the impact of Adobe’s “print anything” philosophy.
PostScript Language
While our study will focus on the PostScript server or implementation, it is important to note the language that the code supports. In (Reid 1988, pg 2), the author states:
The three most important aspects of the PostScript programming language are that it is interpreted, that it is stack-based, and that it uses a unique data structure called a dictionary.
The interpreted nature of the language made it simpler to produce and understand (since you did not need any decompiler to read the code) as well as encouraging experimentation via interactive development. The stack-based model reduced the execution requirements, particularly for memory. Although the Apple LaserWriter infamously had more processing power and memory than the connected Macintosh, resources were at a premium. Further, the content of the stack could be easily modified and composed, allowing programmers great flexibility. The dictionaries allowed existing operators to be replaced or augmented (and then reset to normal for the next job), further providing flexibility to the users.
To give a sense of the language, the code below (source: Rosetta Code) produces a Sierpinski Triangle. Depending on the output device, this will render either to a printed page or a display (Figure A).
%!PS
/sierp { % level ax ay bx by cx cy
6 cpy triangle
sierpr
} bind def
/sierpr {
12 cpy
10 -4 2 {
5 1 roll exch 4 -1 roll
add 0.5 mul 3 1 roll
add 0.5 mul 3 -1 roll
2 roll
} for % l a b c bc ac ab
13 -1 roll dup 0 gt {
1 sub
dup 4 cpy 18 -2 roll sierpr
dup 7 index 7 index 2 cpy 16 -2 roll sierpr
9 3 roll 1 index 1 index 2 cpy 13 4 roll sierpr
} { 13 -6 roll 7 { pop } repeat } ifelse
triangle
} bind def
/cpy { { 5 index } repeat } bind def
/triangle {
newpath moveto lineto lineto closepath stroke
} bind def
6 50 100 550 100 300 533 sierp
showpage

The PostScript code requires less than 700 bytes to describe the image, which can be scaled and translated arbitrarily or, with some tweaking of the parameters, rendered to a greater depth. In comparison, the compressed PNG requires 15,000 bytes of storage (even with space optimization) and a Scalable Vector Graphics representation 2,800 bytes (or 560 bytes gzipped). The SVG representation builds the image out of vector-based triangles, which can be arbitrarily scaled and translated, but SVG lacks the ability to increase or decrease the depth of the fractal.
Study Limitations
Although all historical studies are limited by the unavailability of certain artifacts and the distance of time, there are a few limitations particular to this study. First, Adobe has chosen not to release certain files that are still covered by trade secrets. The distribution is missing the files:
- except.h
- bezier.c
- curvefit.c
- gray.c and .h
- reducer.c and .h
The effect of these omissions is that the software will not build “as-is”. By examining references in existing code, we counted 19 functions or macros that are referenced in the distributed code but are missing implementations.
Secondly, Adobe and CHM have released the code under a custom EULA that prohibits various activities. In personal correspondence with the CHM, we have received authorization to display sections of the source code with our comments as they consider public scholarship to fall under educational use.
Timeline
Contextual Timeline
Table 1: Historical Context Timeline
| Date | Event |
|---|---|
| 1965 | University of Utah’s establishes graphics center of excellence Using a grant from ARPA, the university launches a broad research program into computer graphics. |
| 1971? | Harbor Pilot Simulator. Evans and Sutherland (E&S) awarded contract to build a harbor pilot simulator for the New York Maritime Academy. To populate the 3D database, Warnock’s team invented a stack-based language that created the geometries and textures. |
| 1971 | Xerox invents the laser printer. Laser printer technology enabled high quality, high throughput printing. The first commercial printer came in 1976 (at least one that supported multiple fonts), IBM’s 3800, and soon thereafter by offerings from Xerox and Canon. |
| 1974 | Xerox develops Press. The first successful page description format is developed at PARC, incorporating lessons from two previous systems. Press supports text, with multiple fonts, images, and filled objects to be incorporated on the same page. Over 200,000 documents are created in Press by 1983. |
| 1977 | E&S Design System. E&S evolve the language from the Harbor Pilot simulator into a CAD system. |
| 1977 | TeX Project Launched. In May, Donald Knuth writes a memo describing the core features of TeX, a new typesetting system. This project would see the first major release in 1982 and the design frozen with release 3.0 in 1990. |
| 1978 | JaM invented at Xerox PARC. The John and Martin language is used to experiment with graphical models. This language was inspired by the E&S Design System language and the graphical model inspired PostScript’s model. |
| 1981 | Interpress started. Xerox starts work on a successor to Press. |
| 1981-09 | Command Language Patent filed. John Gaffney files patent for a “Command language system for interactive computer” based on his work for the Evans and Sutherland Design System. |
| 1982-01 | Interpress 82. Specifications for “version 1” of Interpress, Xerox’s language and page description system to replace Press are published for internal consumption. |
| 1982-12 | Adobe Founded. Chuck Geschke and John Warnock found Adobe. |
| 1983-04 | DEC interested in license agreement Gordon Bell of DEC meets with team and expresses interest in PostScript as a printer protocol. DEC eventually licenses the technology. |
| 1983-05 | Steve Jobs visit. Steve Jobs meets with Adobe and expresses interest in PostScript as a printer protocol for the upcoming Apple laser printer. |
| 1983-12 | Adobe signs license agreement with Apple Adobe will provide software for the LaserWriter and ensure PostScript’s quality at 300 dpi. |
| 1984 | PostScript released. |
| 1984 | Linotronic 300 Imagesetter released. First commercial printer to support PostScript. |
| 1984-04 | Xerox announces documentation for Interpress available. Version 2.1 of the Interpress Standard is first released externally. |
| 1985 | PostScript manuals published The “Red” book and “Green” book provide a high-quality reference manual and tutorial for PostScript. The reference manual states that it covers PostScript version 23.0. |
| 1985 | Apple LaserWriter, Aldus Pagemaker 1.0 released. Creatives could now generate documents competitive to commercial printers in quality and without specialized programming or typesetting skills. |
| 1991 | PostScript Level 2 released. Expanded the capabilities and reliability of the language, but saw limited commercial impact as Level 1 satisfied most needs. |
| 1993 | PDF 1.0 released. Increased page throughput and reduced variability by sharply limiting the programming language power. |
| 1997 | PostScript Level 3 released. Last release of PostScript. |
Development Timeline
Based on the file edit history captured in comments within each file, we can attempt to reconstitute the order of development. Table 2, below, lists the creation date (year and month) for each file (denoted in italics) and dates that the file was edited (denoted in normal typeface). The comments do not state what was edited, just the author and date. A file may be listed multiple times in a month depending on the edit history.
Table 2: Development Timeline
| Date | Files Created or Edited |
|---|---|
| 1983-01 | STbuild.c, errors.h, globals.h, postscript.h, procs.h, scanner.c, types.h |
| 1983-02 | array.c, control.c, debug.c, dict.c, error.c, exec.c, math.c, name.c, stack.c, stream.c, string.c, type.c |
| 1983-03 | matrix.c, error.c, errors.h, globals.h, math.c, procs.h, stream.c, types.h |
| 1983-04 | banddevice.c, user.c, xylock.c, banddevice.c, matrix.c |
| 1983-05 | fontcache.c, graphics.c, graphics.h, inputdevice.c, memdevice.c, nulldevice.c, path.c, stroke.c, dict.c, fontcache.c |
| 1983-06 | fontcache.c |
| 1983-07 | fontdisk.c, fonts.h, fontshow.c, math.c |
| 1983-08 | graphicspriv.h, sundev.c |
| 1983-09 | framedevice.c, framedevice.h, image.c, versatecdev.c, versatecdev.c |
| 1983-10 | fontdisk.c, fontshow.c, framedevice.h, sundev.c, user.c |
| 1983-11 | device.c, font.c, fontbuild.c, fontcrypt.c, graphpak.c, unix.c, vm.c, error.c, errors.h, framedevice.h, graphics.c, graphpak.c, image.c, inputdevice.c, memdevice.c, nulldevice.c, stroke.c, types.h |
| 1983-12 | banddevice.c, banddevice.c, device.c, font.c, fontcrypt.c, globals.h, inputdevice.c, matrix.c, matrix.c, memdevice.c, nulldevice.c, postscript.h, sundev.c, unix.c, user.c, versatecdev.c |
| 1984-01 | STbuild.c, font.c, graphics.h, graphics.h, math.c |
| 1984-02 | array.c, control.c, debug.c, device.c, dict.c, exec.c, fontbuild.c, fontbuild.c, fontcache.c, fontdisk.c, fonts.h, fontshow.c, framedevice.c, framedevice.c, graphics.c, graphicspriv.h, graphicspriv.h, image.c, name.c, path.c, path.c, procs.h, scanner.c, stack.c, stream.c, string.c, stroke.c, type.c, types.h, vm.c, xylock.c |
This timeline suggests that the major language components and processing loop for PostScript were completed in the first three months, or January to March 1983. The team then began focusing on the graphics engine, including printing to their borrowed LN01 laser printer, as denoted by the work on the banddevice and xylock files, as well as graphics, path, and stroke. This effort took most of April and May. Work on fonts, at least initial support, started in May and was the predominant effort in June and July. In August, September, and October, the team started rendering images on the Sun-1 framebuffer, along with additional improvements to fonts. November sees the last big fleshing out of the design, with additional work on fonts and graphics, refinement of interfaces to input and output devices, and virtual memory support for running within restricted devices. The last three months, December to February 1984, see very diffuse efforts, implying integration changes, performance enhancements, and bug fixes.
Developers and their Influences
In the forward to the 1985 PostScript Language Reference Manual, John Warnock attributes the beginning of the PostScript design to John Gaffney and the Design System, developed at Evans and Sutherland. Furthermore, he notes the contributions of JaM, a language he developed with Martin Newell at Xerox. PostScript came from a rich intellectual pedigree and benefited from prior art.
Co-Founders
Charles Geschke and John Warnock were the two co-founders of Adobe. Both were “technical” founders and brought relevant expertise to the design and implementation of PostScript.
Charles (Chuck) Geschke
Charles (Chuck) Geschke was awarded a PhD in Computer Science from Carnegie Mellon University. His thesis was titled “Global Program Optimizations” and his advisor was William Wulf.
Joining Xerox PARC in 1972, he created the Imaging Sciences Laboratory in 1978, and hired John Warnock soon after. While at PARC, Geschke was involved in the design and implementation of a Mesa language compiler. Mesa features a module system and a strong type system. Although Mesa was not used to implement PostScript (the language was proprietary to Xerox), Mesa-isms can be seen in the PostScript code as described in the later section, “Programming Language and Dialect”.
The majority of changes in the version 1.0 source code are attributed to Geschke.
John Warnock
John Warnock was awarded his PhD from the University of Utah in 1972 for the thesis “A hidden surface algorithm for computer generated halftone pictures”. His advisor was David Evans who, along with fellow committee member Ivan Sutherland, hired him into Evans and Sutherland. This was a heady period as the University of Utah had been recently established as a national center for computer graphics research by DARPA and Evans and Sutherland were pioneering many graphical and computer simulation techniques.
Warnock stayed at Evans and Sutherland for six years. One of the earliest influences on PostScript’s design was the Harbor Pilot Simulator. Warnock’s team was responsible for creating the 3D environment for the harbor. A member of Warnock’s team, John Gaffney, developed a stack-based language that could populate the database. This language later developed into The Design System (1976).
In 1978, Warnock joined Xerox PARC and Geschke’s team. Along with Martin Newell, Warnock developed JaM, a programming language based on The Design System. JaM influenced Interpress, a programming language and page description format based on learnings from Xerox’s Press system. The paper (Warnock and Wyatt 1982) describes a graphical model used in some Xerox efforts that later is the basis for PostScript’s graphical model.
Contributors to Version 1.0
Using the changelog attributions, the list of developers (excluding the two co-founders) for version 1.0 were Tom Boynton, Doug Brotz, and Andrew Shore. In (Warnock and Geschke 2019)’s description of the founding of Adobe, the team listing includes Tom Boynton and Dan Putnam (both described as electronic engineers), Doug Brotz, and Bill Paxton, but drops Shore. ACM’s Software System Award for PostScript includes the two co-founders and Brotz, Paxton, and Edward Taft. Paxton joined Adobe in 1983 and Taft in February 1984, both early enough to make contributions to PostScript but missed contributing to the 1.0 source code.
Tom Boynton
Tom Bonyton is credited with the original versions of banddevice.c and math.c, but edited other files as well. A band device does not support representing the page as a full array of pixels, but rather requires being fed a sequence of bands with one being consumed while the program produces the other. DEC had lent Adobe an early laser printer (LN01, based on the Xerox 2700) which, since it was severely limited in memory, used two band buffers for printing. Boynton worked at Xerox PARC previously to Adobe, but we were unable to find additional biographical details. It is likely that when Adobe decided to be a software-only firm, the electronic engineers left for other companies.
Doug Brotz
Doug Brotz was awarded a PhD in Computer Science from Stanford University. His thesis was on automated theorem proving. After a period of time at the University of Arizona, he joined Xerox in 1977. This soon led him to PARC where he worked on the Laurel email client. Laurel was implemented in the Mesa programming language. During the development of Laurel, Brotz met Warnock when Warnock recommended using Laurel’s plugin capability to integrate with JaM and allow the sending of graphics in email messages.
He joined Adobe in March 1983 and made many contributions to PostScript, particularly in graphics and font-handling. His earliest contributions date to May 1983. Based on the changelog, he is the second most prolific author behind Geschke.
For someone who made many fundamental contributions to PostScript, Brotz surprisingly lacked any background in graphics programming. He recounts his involvement with the reducer algorithm in (Perry 1988):
“About a week after I had joined Adobe in 1983,” Brotz recalls, “John Warnock mentioned this rather important algorithm that had to be written. And I, with no graphics background, volunteered. Several months later, older and wiser, I realized it truly was one of the world’s hardest problems.”
But Brotz did not give up, and he says, “We have now an exactly correct reducer algorithm. It is the heart of the graphics system in PostScript.” And a tally Brotz keeps reveals that no bugs have been discovered in the Reducer in more than two years.
Andrew (Andy) Shore
We were unable to find many details about Andrew Shore. The changelog indicates he wrote the initial version of the unix.c file and made edits to fontbuild.c. He was active on the fa.Laser Lovers USENET channel in 1984 and 1985 using an Adobe email address. Adobe celebrated his presence in a 2021 blog post, but the posting yields few biographical details.
However, he is anecdotally remembered via “Andy’s Stupid Input Device.” (Perry 1988) recounts how PostScript came to support scanners and other graphic input devices:
As originally conceived, PostScript was to have been independent of the output, but not the input, device. Warnock had thought that PostScript, to take in scanned images, would need to contain information about a wide range of optical scanners. But Brotz, after programming the parameters of just two of many scanner types, realized that the task was not only horrendous and repetitive but ate up a lot of memory.
Andy Shore, an Adobe computer scientist, overheard him complaining one day and suggested writing a PostScript procedure that would pretend that it was an input device and spit out the image information in a standard format, regardless of the characteristics of the actual standard. Brotz did not think it would work and “Warnock promptly labeled it ‘Andy’s Stupid Input Device.’”
Still, Brotz thought it might be helpful for generating test patterns, and when he implemented it, “it turned out that Andy’s Stupid Input Device was the lowest common denominator and all the special-case code could disappear.” Problems arise only when the image data has been compressed for transmission or storage; the programmer then has to insert a routine to decompress the data before it is handed to the image algorithm.”
This anecdote demonstrates two aspects of PostScript; first, the interface designed around a “lowest common denominator” of functionality facilitated a wide variety of devices to plug-in to the system, greatly increasing its value. Furthermore, supporting compressed images was a matter of composing procedures, a matter very straight-forward using the stacks and dictionaries within the language.
The Design System
John Gaffney was a member of Warnock’s Evans and Sutherland team when they were building the Harbor Pilot Simulator. The project was behind schedule and they needed to rapidly build a 3D model of the harbor. Gaffney built a language that programmatically constructed database elements. Coupled with a menu-driven user interface, the team finished the database in time. Later, the language was expanded into the Design System. Gaffney’s 1981 patent “Command language system for interactive computer” describes “The Design System”’s language thusly:
A command language system is disclosed wherein memory stacks register specific definitions for generic names, which definitions are appropriately selected in timely response to a name, on the basis of stack arrangement. A structure is included for searching the stack in order and detecting the first definition for a name of current interest. Thus, the stack is used to define the order of the name searching. As a consequence, in the interpretation of command languages, the user is given control over the context in which the names are executed. Specifically, a command program will behave according to the definitions of the commands in a current context. The system further includes structure for deleting definitions from the stack which have been used and for sensing the bottom of the stack as a function of control.
Put simply, the language defines stacks of dictionaries under the programmer’s control. When a name is looked up, the stack is searched in order. Thus, a programmer can replace or augment functionality by adding or deleting entries within a dictionary, creating new dictionaries, and changing the order of dictionaries within the stack. Along with an interactive interface and a defined entity model, the earlier Harbor Pilot Simulator implementation facilitated rapid creation of a 3D database.
Only one copy of The Design System was sold and, when the director died, the project ended (Perry 1988). However, the key aspects of the Design System were identified in (Reid 1988) as the key aspects of the PostScript language.
Xerox
In the book Introduction to Interpress (Sproull and Reid 1983, 221-223), the authors describe the lessons learned over multiple iterations of publishing tools at Xerox. Although the Adobe developers may have disagreed with some of these lessons, they all, especially the founders, would have been aware of them.
Shortly after PARC was founded in 1970, one of the employees developed the listing program which translated ASCII documents into a raster image for a printer. Users could insert inline escape sequences to control font selection, insert images, and control simple formatting choices like subscripts and superscripts. However, the program made many stylistic choices for the document which often did not comply with the user’s wishes. The developers learned that style and layout decisions should not be coupled in the same layer with rasterization. For instance, PostScript does not include logic for text wrapping; those decisions are handled at a higher level.
PARC engineers also developed systems that were deeply tied to a single printer’s capabilities. Users sent page descriptions tailored to that printer. Although a user could maximize the performance of a given printer, this approach required too much from users and was considered to be too low-level.
Based on these learnings, PARC engineers designed Press in 1974. They designed Press to be:
- Device independent
- Single file containing embedded text and graphics
- Font libraries were delegated to the printer
- Un-opinionated by making no formatting decisions
Press was very successful. The authors state it was used in over 200,000 documents, many created by non-technical employees.
In 1981, limitations in Press led to a new design, Interpress. Interpress differentiated itself from Press by:
- Press is a data structure while Interpress (and PostScript) is a program
- Press has a single coordinate system rather than supporting multiple coordinate systems. PostScript and Interpress could translate and scale multiple pages onto a single page programmatically.
- Press’s graphic model only supports filled objects and pixel arrays
- Press lacks a
correctfacility for correcting font approximations - Press files contain both printer data and application information
PostScript and Interpress were very similar in the first three bullet points. PostScript approached fonts differently than Interpress and thus did not need a correct facility.
With the benefit of hindsight of the success of PDF, we may question why Interpress and Postscript both chose to be a program rather than just a page description. In (Warnock 2012), the author lists the advantages and disadvantages of program as a representation:
Disadvantages:
- Programs might never stop
- Indeterminate number of pages can be produced
- Program dictates order of pages produced
Advantages:
- Operators can be redefined, so programs can fix or extend the language
- Programs can interpret other printer protocols and emulate them
- Character encodings (e.g. Japanese, Farsi) can be implemented programmatically
- Subroutines can efficiently implement sub-components on pages
The second advantage was used for the Apple LaserWriter as a PostScript program could read and translate Apple’s QuickDraw graphical model into the PostScript graphical model, saving time and effort versus a separate translation program.
Development and Test Environment
Adobe engineers developed on a leased VAX 750 running Berkeley Unix. For testing, the team used a Sun-1 workstation that included a primitive frame buffer and a LN01 laser printer borrowed from DEC (Perry 1988). The LN01 was a rebranded Xerox 2700.
The printer was capable of 300 dpi and 12 pages/minute. It used an Intel 8086 processor with either 64kb or 256kb of RAM and used two band buffers to enable reading additional data while printing the contents of the other buffer (Xerox 2022).
Roket: In the file
framebuffer.c, there is a function calledpsFrameToRoketwhich is only enabled for Sun builds. The function outputs a bitmap to/dev/roketand uses ioctl to adjust values such as width and height. We have been unable to determine what hardware or interface is being used here as roket isn’t a term in the Sun-1 user manuals.
Design and Source Code
The following sections analyze the version 1.0 source code artifacts.
Physical Form
Per David A. Wheeler’s SLOCCount, the distribution contains approximately 12,000 lines of C code (.c and .h files) and a makefile. Per cloc, there are 1,171 lines of comments. However, since each file contains a commented copyright notice and edit history, there are less than 600 “true” comments in the code.
The makefile organizes the source files into five groups: kernel, graphics, device, fonts, and user. The kernel files implement the basic language and core operators, as well as the virtual memory subsystem. The graphics files implement paths, strokes, matrices and other graphic primitives, and the reducer. Device files handle input and output devices. Font files handle reading, caching, and rendering fonts. User files handle some hosting concerns on Unix machines.
Although we are missing some files, we can count lines of code per file group (Table 3) to get a sense of the complexity of the groups, at least once they are rendered to code. Per comments from the co-founders, font handling and graphics reduction were considered open problems as they started implementation. Although they had experience with both problems at Interpress, the co-founders considered the previous solutions as having insufficient quality and flexibility. Legally, the co-founders also wanted designs that were free from Xerox intellectual property. Adobe licensed the Design System, so the “kernel” was legally protected.
Table 3: Lines of Code by File Group
| File Group | Lines of Code | LOC Percent | Notes |
|---|---|---|---|
| Kernel | 5564 | 46 | |
| Graphics | 2410 | 20 | Missing gray and reducer |
| Fonts | 2014 | 17 | Missing bezier and curvefit |
| Device | 1647 | 14 | |
| User | 123 | 1 |
Oddball Files
The distribution includes four “oddball” files or files that do not seem to properly belong to the software. These files are begin.c, end.c, bug.c, and padPS.c. None include the customary copyright header or comments describing authorship or edit history. None are included in the Makefile. Due to their nature, we usually excluded them from code analysis.
The pair begin.c and end.c each define a single function, BEGIN and END respectively, that simply sets the local variable i to zero. Based on code in control.c, these two functions are only included if the release flag is not set and are used as part of some performance monitoring function.
The standalone program bug.c tests that the value of a local unsigned short is equal to an extracted short from a struct bitfield. The PostScript code uses struct bitfields in various places, so this was likely used to either test a potential compiler bug or to verify some behavior of the C language.
Another standalone program, padPS.c, reads a hexadecimal number from the command line arguments and two decimal numbers from stdin. The program then performs a short calculation of a padding value and either prints out the padding value or an error message. Since the calculation does not use the second number decimal number, this was likely some ad-hoc program used during development.
There are two programs that have their own entry points (main functions) and have the standard copyright headers, but are not part of the makefile. These are STbuild.c and fontcrypt.c. The purpose of STBuild.c is to produce scan tables incorporated in scanner.c. Because the output tables are incorporated into the code, rather than being generated every build, the code served a development purpose but was not included in the PostScript program itself. The fontcrypt.c programs takes a file, presumably a font file, and encrypts it by xor-ing each byte with a pseudo-random byte (via a linear congruential generator). This process can be reversed in scanner.c or fontbuild.c which can reproduce the random byte stream. The encryption method (and constants) were updated by the time the Font 1 Specification was released (Adobe Systems Incorporated 1993).
Architecture
John Warnock advocated for a Unix-like approach to the PostScript design. Thus, PostScript’s design mirrors a Unix filter in that it reads from stdin and writes to either stdout or stderr. Although PostScript is primarily used to interact with printers, the design does not include features related to queuing multiple jobs or keeping track of spend. Instead, the assumption is that an intermediary program would handle those jobs. This act of composing functionality through multiple programs is also part of the Unix philosophy. Figure B describes the deployment architecture.
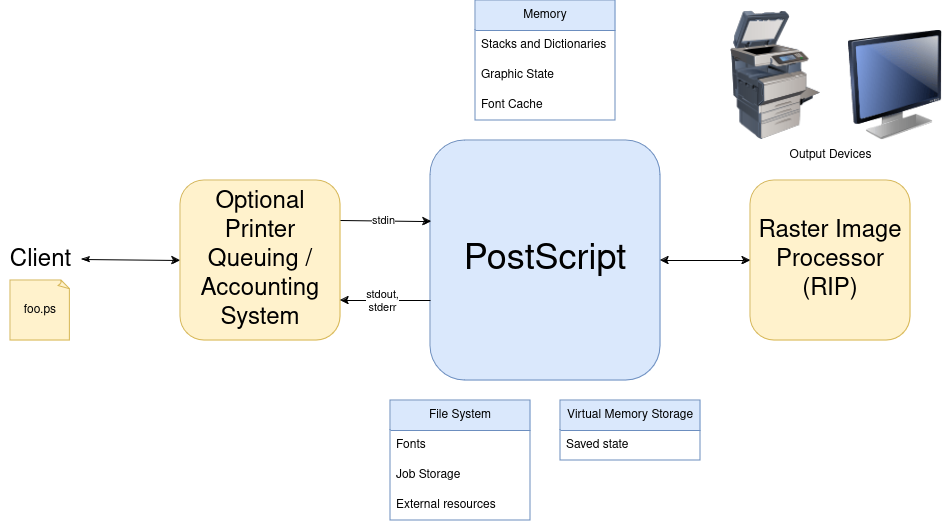
Since there is a large cost to start-up (primarily due to loading fonts), PostScript is designed to initialize once and then cheaply reset to a known state after every job. (Since many implementations printed a test page on start-up, minimizing the number of start-ups also helped save ink and paper.) The virtual memory storage is a copy of the memory or global state of the program.
On the right-side of Figure B is the raster image processor (RIP) which translates the rasterized pages into the appropriate final representation for the output device. The 1.0 source code does not include the acronym RIP nor includes the full term. However, RIPs were part of the architecture by the time the first commercial printers became available. (Industry use of the term RIP is confusing. A RIP could be an embeddable component which includes PostScript, or RIP could be equivalent to a PostScript output device.)
With simple streaming inputs and outputs, PostScript could be embedded within other systems flexibly and remain agnostic about client interfaces. As a streaming system, PostScript could operate in both a batched and interactive manner. This design was attractive to both creatives and printer manufacturers. For the former, they could target a single language for output and then take that file to any printer (or similar device). Manufacturers could add special sauce at the RIP layer and continue to improve quality and throughput on the output-side without requiring changes to the input. Printer services could embed PostScript into their printing orchestration services and anyone could print, at whatever quality they could afford.
Programming Language and Dialect
The source code is written in K&R C (the first Standard Draft was released in 1985 and the first standard followed in 1989). However, the developers used the preprocessor and typedefs to make the language more Mesa-like. Mesa was a systems programming language at Xerox and Charles Geschke had been deeply involved in the design of the language and the compiler. The PrimeSize function from dict.c serves as an example of this dialect:
private cardinal PrimeSize(s)
cardinal s;
{
cardinal i, size = (s <=500)? (s + s/2 + 1) : (s + s/5 + 1);
if (MAXdictLength != 2000)
BUG("This version not prepared for dictionaries over 2000 elements!");
if (s > MAXdictLength) ERROR(limitcheck);
switch (s) {
case 0: return 3;
/* [...] */
case 10: return 13;
endswitch}
i = 0;
until ((size >= primes[i])&&(size < primes[i+1])) {i++;}
return primes[i];
}
Mesa featured a strong module system and the developers wished to capture the documentary value of modules, even if the compiler lacked the semantics. The developers marked functions as private or public and these mapped to C’s static or default scope. If a function did not return a value, they used procedure as the return type. The developers typedef the basic types to their Mesa names, such as cardinal for unsigned short int, real for float, and character to unsigned char.
Also similar to Mesa, the BUG and ERROR procedures raised signals. The endswitch macro added an empty default case while the until macro replaced the clause with a while loop and negated the expression.
Historical Constraints
The rasterization process requires encoding the color value (which admittedly fit within a single bit for the initial devices) for each pixel or dot on a page. The storage requirements, if the entire page was rasterized at once, were significant at the time (Table 4). Thus, the design of PostScript had to accommodate limited memory capacity. Indeed, their test printer, the LN01 / Xerox 2700, could only hold two sets of 32 scan lines of 300 dpi at a time. Although the price of memory soon collapsed (Figure C) in 1984, prices were relatively stable in 1982 to 1984 during the development of PostScript. Without the collapse in prices, laser printers would have not been commercially viable and the desktop publishing revolution would have been postponed.
Table 4: Storage Requirements for Rasterization on Extant Devices
| Output Device | Resolution | DPI | Bytes to Raster One Page |
|---|---|---|---|
| Macintosh 128k | 512x342 | 72 | 21,888 |
| LaserWriter | 7.66"x10.16" | 300 | 875,475 |
| Linotronic 300 | 8.5"x11" | 2540 | 75,403,075 |
(The LaserWriter had a non-printable border of 0.42" per the user manual.)

Interesting Algorithms and Designs
Reading through the source code, we found two items that are both interesting and representative of the whole: the design for handling input devices and the mini-reducer algorithm for strokes.
Input Device
Although it is unclear if this code represents “Andy’s stupid input device,” the InputDevice design demonstrates many of the common patterns seen within the code. Input devices are used to insert graphics into the document.
The definition of an input device (from graphics.h):
typedef struct
{
procedure (*SetUpImage)( /* StreamHandle sh; */ );
/* function that sets up the input device for subsequent calls to all
other input device procedures. The StreamHandle is assumed to
refer to an open stream on an image file (of the type understood by
this input device) positioned at the beginning. */
procedure (*InputMatrix)( /* Matrix matrix;*/ );
/* function that fills in the supplied matrix with values that map
from input DeviceCoord's to positions in the unit square in user
space. */
ImageSlice (*NextSlice)();
/* function that returns an ImageSlice that refers to a portion of the
current image. A returned ImageSlice->width of zero indicates that
no more image remains. The image algorithm requires that a one-pixel
buffer zone surround the rectangle actually used for imaging. Thus,
the minimum useful ImageSlice returned must be at least 3 pixels
high and wide. At internal boundaries in the image, the input device
must buffer two lines at the boundary of a previous slice and
include those lines in a subsequent slice. I.e., the input device
must supply slices consisting of a rectangular tile and a one-pixel
wide frame around that tile such that the tiles completely cover the
input image. The ImageSliceRec and pixel storage returned by this
function may be reused for subsequent calls. */
}
InputDeviceRec, *InputDevice;
An input device is an interface, implemented via function pointers within a struct, that contains three operations: a SetUpImage function that “constructs” the internal data structures via a handle to a stream, a InputMatrix function for accessing the transformation matrix (a Matrix is for transformation, not general matrix storage), and a NextSlice function that acts as an iterator for the output pixels. Since images can easily exceed the memory capacity of devices of the time, and potentially exceed the disk storage capacity, iterators are commonly used to “chunk” large amounts of data into manageable increments.
We can see how the input devices are used through the image PostScript command. image takes five arguments: width and heigh of the image, the bits per pixel, the transformation matrix, and a PostScript procedure for the image data. For example, this example from Paul Bourke renders a small document icon:
100 200 translate
26 34 scale
26 34 8 [26 0 0 -34 0 34]
{<
ffffffffffffffffffffffffffffffffffffffffffffffffffff
ff000000000000000000000000000000000000ffffffffffffff
ff00efefefefefefefefefefefefefefefef0000ffffffffffff
ff00efefefefefefefefefefefefefefefef00ce00ffffffffff
ff00efefefefefefefefefefefefefefefef00cece00ffffffff
ff00efefefefefefefefefefefefefefefef00cecece00ffffff
ff00efefefefefefefefefefefefefefefef00cececece00ffff
ff00efefefefefefefefefefefefefefefef00000000000000ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efef000000ef000000ef000000ef0000ef0000efefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efef000000ef00000000ef00000000ef000000efefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efef0000ef00000000000000ef000000ef0000efefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff00efefefefefefefefefefefefefefefefefefefefefef00ff
ff000000000000000000000000000000000000000000000000ff
ffffffffffffffffffffffffffffffffffffffffffffffffffff
>}
image
The PostScript image command is implemented by the psImage procedure in image.c (the developers use the ps prefix to identify functions that are called as PostScript commands). When invoked, psImage processes its arguments and initializes the input device with the image data and the transformation matrix. Then, for each slice (rectangular section of the input image), the code defines a new trapezoidal path with transformed coordinates, and then calls Reduce. Although Reduce is not included in the source code distribution, we know it would rasterize the image onto the output by pulling from the input via the inverse transformation. (We have added //-style comments for clarity.)
private procedure psImage()
{
// ... setup ...
(*gs->inputDevice->SetUpImage)(sh);
(*gs->inputDevice->InputMatrix)(&imageMatrix);
// ... math to transform inputs to outputs and for the inverse ...
do
{
curImageSlice = (*gs->inputDevice->NextSlice)();
if (curImageSlice->width == 0) break;
NewPathIsClip(true);
FeedPathToReducer(&gs->clip, CallNewPoint, ReducerClosePath);
c.x = curImageSlice->origin.x + 1; c.y = curImageSlice->origin.y + 1;
NewPathIsClip(false);
CallNewPoint(TransformCoord(c, &imageTransform));
c.x += curImageSlice->width - 2;
CallNewPoint(TransformCoord(c, &imageTransform));
c.y += curImageSlice->height - 2;
CallNewPoint(TransformCoord(c, &imageTransform));
c.x -= curImageSlice->width - 2;
CallNewPoint(TransformCoord(c, &imageTransform));
ReducerClosePath();
Reduce(CallDeviceImageTrap, true, false);
} while (true);
} /* end of psImage */
The code is surprisingly generalizable — once an image is rasterized, it can then be inserted into the document. Later versions of PostScript included support for compressed images, but that was more for convenience than necessity. As long as chunks of the image could fit within memory, they could be translated into the final output, even with additional transformations.
Mini-Reducer for Simple Quadrilaterals
The “heart of the graphics engine,” the reducer algorithm translates arbitrary shapes into a raster image. Although the reducer algorithm is still considered a trade secret by Adobe forty years later, and thus not part of the source code release, (Warnock and Geschke 2019) provided a high-level description of the algorithm. The algorithm uses a plane-sweep approach to convert arbitrary shapes into non-overlapping trapezoids. The trapezoids are then rasterized to the final output. The original implementation used floating point, but this led to errors where line segments would “braid” around each other. Apple loaned one of their programmers, Jerome Coonen, who helped convert the algorithm to use fixed point.
While the full reducer is absent, the source code does include a “mini-reducer”, as it is commented, within stroke.c. One of the better commented sections of code, the algorithm reduces simple cases of convex quadrilaterals (i.e. a four-sided polygon with all interior angles less than 180 degrees) that lie completely within the clipping region to a rasterized image. In the code below, the /* comments are original while the // comments are added by the author.
|
|
QuadTrap is a macro defined as:
#define QuadTrap(qcp1,qcp2) { \
xtr = qcp1->c.x; \
// ptr1 is "next" while ptr2 is "previous" in the doubly-linked list of the path
qcptr = (qcp2->ptr1 == qcp1) ? qcp2->ptr2 : qcp2->ptr1; \
xtl = qcp2->c.x \
+ Fix(FReal(yt - qcp2->c.y) * FReal(qcptr->c.x - qcp2->c.x) \
/ FReal(qcptr->c.y - qcp2->c.y)); \
if (xtr < xtl) {tfixed = xtr; xtr = xtl; xtl = tfixed;} \
(*gs->outputDevice->ColorTrap) \
(yt, yb, xtl, xtr, xbl, xbr, gs->color, gs->screen); \
yb = yt; xbl = xtl; xbr = xtr; \
}
Figure D illustrates how an example quadrilateral is filled with trapezoids. The left-most image traces the algorithm through line 26, the second through line 30, the third through line 43, and the fourth through the final statement of the function on lines 45 and 46. In this algorithm, a trapezoid may be a triangle (one side has length zero) and, in this example, two triangles are produced. Starting from the bottom of the polygon, the algorithm splits the polygon via horizontal scan beams based on the polygon’s vertices. The next trapezoid’s bottom edge is based on the former trapezoid’s top edge. Since the algorithm is only given limited, albeit common, inputs (convex quadrilateral completely within the clipping region), the algorithm only needs to handle various rotations of the quadrilateral.
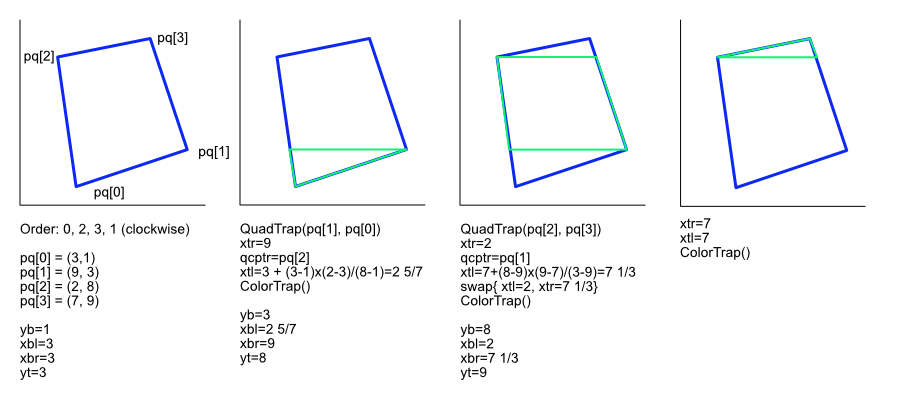
A similar algorithm for decomposing convex polygons into trapezoids is briefly described in Parallel Processing and image synthesis and anti-aliasing, while a more general version is Vatti’s polygon clipping algorithm (A generic solution to polygon clipping). We consider it possible that Adobe’s reducer is very similar to Vatti’s algorithm as both use a plane sweep approach.
Implementation-wise, it is notable that while the algorithm stores positions in fixed point representation, the actual operations are performed using floating point operations. The FReal macro casts the argument to a float and then divides by 1<<16, while Fix does the opposite by casting the argument to an integer and multiplying by 1<<16. In both cases, the compiler could highly optimize these operations as they are modifications by powers of two.
FastFillQuad avoids making any function calls except for the ColorTrap calls. Macros are used to encapsulate reused code but make free use of referencing and changing variables that are not passed as arguments. While unhygienic, code profiling may have indicated the loss of clarity as worth the increase in performance.
Alternative Paths / Competitors
While there were a variety of proprietary printer languages that supported various raster effects, the only digital competitor to PostScript was Xerox’s Interpress. The non-commercial TeX project solved similar issues of rasterization using Device Independent files, but their solution had limited capability.
Interpress
An observer in the mid-1980s would have likely considered PostScript the underdog to Xerox’s Interpress. Interpress had several advantages: it had been under development for at least twice as long as PostScript, was funded by Xerox which had pioneered many desktop publishing technologies and had lots of capital, and had a captive PARC community to validate the design. However, Xerox management dithered away their advantages (as they did for the rest of their PARC investment) and Adobe won.
Ignoring the business side, based on their technical merits, how did Interpress and PostScript compare? In a pair of Usenet postings to the fa.laser-lovers newsgroup in 1985, Brian Reid and Jerry Mendelson compared the two systems. Brian Reid based his analysis on the publicly released 1984 Interpress manual (which he noted to his surprise was created via Press, not Interpress). Reid had worked for Xerox as a consultant on the Interpress project alongside Geschke, Warnock, Lampson, and Sproull. Sproull was formerly Reid’s thesis advisor and Reid later wrote the “Green Book,” an introduction to the PostScript language. When Mendelson wrote his reply, he was a retired Xerox research fellow, but an active Xerox consultant. He had also worked on the transition of Interpress from a research project into a commercial product. Thus, both writers had first-hand experience with the technology and Xerox’s culture.
Both writers agreed that Interpress had better support for interacting and controlling printers, such as controlling page order, informing accounting systems of printing expenses, and selecting optional features such as stapling. Interpress files also imposed a structure on the program that meant the expected page count could be discerned from the structure and individual pages could be printed in any order. (This feature would be part of the PDF format.) While the lack of this structure could be used to an advantage for PostScript, for instance if a PostScript program was translating another format such as QuickDraw to itself, commercial printers and companies with shared printers appreciated the deterministism of Interpress.
Mendelson considered Interpress' binary encoding format superior to PostScript’s character stream due to the binary format’s reduced space requirements. Mendelson also considered the binary format a better fit for the Xerox Network Systems environment and, indeed, Interpress supported fetching resources remotely via XNS paths, while PostScript required users to place any external files into the printer’s local filesystem (if it existed). Reid was more ambivalent, treating the two formats as expressing different trade-offs.
Language-wise, both PostScript and Interpress were stack-based languages with very similar functions and design. Both writers considered PostScript more flexible and “open” as users could write operators that replaced system operators and PostScript could generate and execute its own code.
Graphically, although both systems had similar origins, PostScript supported curves and arbitrary rotations of objects in 1985, while Interpress did not. Mendelson expected Interpress to close the gap over time, while Reid wondered why the gap existed at all since the underlying algorithms were publicly documented and Interpress had had more development time.
Interpress did not document its approach to fonts in 1985, so Reid was unable to compare the two systems, but Mendelson considered their approach to fonts equivalent. However, if we look at how Interpress handled fonts as described in the 1988 Interpress: the Source Book, fonts were restricted to 90 degree rotations in the Commercial and Publication feature sets. Only the most expensive (and limited in availability) Professional feature set supported arbitrary rotations. Further, the book warns that fonts may drift over time and, if a requested font is not available, the Interpress system will choose an approximate font. This means that character spacing and alignment may be broken if a different font than the original is chosen. Interpress contained a correct operator that attempted to fix these issues, but PostScript, with the ability to embed fonts, never required a similar function.
The strongest technical advantage for Interpress was the document structure, which PDF incorporated in the early 90s. However, PostScript’s adaptability was highly useful for integrating systems at the time, such as Apple’s QuickDraw. In terms of the other technical aspects, the fact that PostScript was fully-featured and available was more important than features that were expected to be as good or better.
Device Independent (DVI) Files
Designed in 1979 as part of the TeX project, Device Independent (DVI) files act as an intermediary page description language. DVI files are read by a driver, which could render the DVI to the screen, a printer, or another representation. DVI shares similar advantages as the later developed PDF standard in that, while the format programatically builds a page, the language is not Turing-complete and thus can be interpreted with predictable performance, capacity requirements, and assurance that processing will terminate. Additionally, the page count is fixed and each page can be rendered in any order.
However, unlike PostScript and PDFs, DVI does not have a means to embed fonts. Fonts can only be referenced from DVIs, meaning they must be installed before being rendered. Further, DVI only supports rectangles as graphics. Graphics are normally embedded within the file as a ‘special,’ and the driver is responsible for rendering them. DVI was never a real competitor to PostScript, but rather DVI was a bridge from TeX to PostScript, as authors would embed PostScript as the graphics format and convert everything to PostScript (and later PDF) for the printer.
“Print Anything” Philosophy
The founder’s disagreements with Xerox may be boiled down to a philosophical difference between “print anything; throughput be damned” and “print most things; preserve our business model”. If a Press document was too complex for the printer, the job would be rejected. Xerox’s primary business billed by pages printed and thus throughput was key. This philosophy was carried forward in Interpress by limiting functionality by market segments and restricting the flexibility of the programs to improve page rendering times. In contrast (Perry 1988):
“Throughout the design of PostScript, speed was regularly traded off to ensure that any image would print. The group reasoned that if they built in all this functionality, they could eventually improve the performance; but if they left out functions, they might never be able to add them back in.”
Within the source code, we find the building blocks of documents such as paths and sampled arrays are treated in the most general of fashion. This generality imposes more work on the program (and on development and testing effort), but the end user benefits by having fewer arbitrary limits placed on their design and creativity.
For example, PostScript decomposed fonts into paths. PostScript allowed paths to be translated, rotated, skewed, and scaled arbitrarily. In contrast, contemporary systems treated fonts as a special case and might allow fonts to be rotated 90 degrees, but heavily restricted scaling and skewing. As part of their market segmentation, Interpress only allowed font rotation by 90 in their lowest priced offering. (It is unclear if the Interpress code supported arbitrary rotation or not; a full-featured version was never released.) Decomposing fonts into paths required inventing new algorithms and, to maintain quality, entirely new ways of rendering fonts. Creatives immediately embraced the flexibility. This flexibility was a key competitive advantage for Adobe until the Font War of the 1990s led to competitors implementing similar algorithms.
Limits of “Print Anything”
As a Turing-complete language, PostScript programs could exceed the limits of the device, either by exceeding the stack depth, requiring more than the allocated number of dictionary keys, or otherwise exhausting memory or patience. The “Red Book” documented many of these static limits. The same language power, however, allowed programmers the possibility of rewriting the program to fit within the device’s capabilities.
Deployment and History after Version 1.0
After 1.0, PostScript’s font handling algorithms were overhauled and dramatically improved in quality. PostScript was embedded into Apple’s new LaserWriter in 1985 and, three years later, had been adopted by 23 manufacturers (Perry 1988). Typefaces proved to be a fertile marketplace as foundries converted their back catalogs into digital forms and designers reveled in the freedom to easily experiment with new fonts. Adobe released two major updates to PostScript in 1991 and 1997, improving reliability and expanding support for color, page support, and ways to embed images and other media.
Adobe’s introduction of PDF in 1993 began to obsolete PostScript. PDF used the same graphics model as PostScript, but dropped the Turing-complete language. PDF could thus be printed at the same or higher throughput as PostScript, but also gained the advantage that individual pages could be referenced (an advantage Interpress had) and rendered separately. As PDFs gained support for forms and interactivity, clients adopted PDFs as a key workflow technology and their use exploded in popularity.
References
(Adobe 1993) Adobe Systems Incorporated. 1993. “Adobe Type 1 Font Format.” Addison-Wesley Publishing Company, Inc. https://adobe-type-tools.github.io/font-tech-notes/pdfs/T1_SPEC.pdf.
(Perry 1988) Perry, Tekla. 1988. “Inventing Postscript, the Tech That Took the Pain out of Printing.” IEEE Spectrum, May 1, 1988. https://spectrum.ieee.org/adobe-postscript.
(Reid 1988) Reid, Glenn. 1988. PostScript Language Program Design. Addison-Wesley Publishing Company, Inc.
(Sproull and Reid 1983) Sproull, Robert F., and Brian Reid. 1983. Introduction to Interpress. XSIG 038306. El Segundo, CA: Xerox Corporation. http://www.bitsavers.org/pdf/xerox/interpress/XSIG_038306_Introduction_to_Interpress_Jun1983.pdf.
(Warnock and Wyatt 1982) Warnock, John E, and Douglas K Wyatt. 1982. “A Device Independent Graphics Imaging Model for Use with Raster Devices.” Proceedings of the 9th Annual Conference on Computer Graphics and Interactive Techniques 16 (3): 313–19. https://doi.org/10.1145/965145.801297.
(Warnock 2012) Warnock, John E. 2012. “Simple Ideas That Changed Printing and Publishing.” Proceedings of the American Philosophical Society 156 (4): 363–78. http://www.jstor.org/stable/23558230
(Warnock and Geschke 2019) Warnock, John E, and Charles Geschke. 2019. “Founding and Growing Adobe Systems, Inc.” IEEE Annals of the History of Computing 41 (3): 24–34. https://doi.org/10.1109/MAHC.2019.2923397.
(Xerox 2022) “The Xerox 2700 Story.” 2022. Association of Retired Xerox Employees. https://archive.org/details/the-xerox-2700-story.